



Google je otkrio niz sigurnosnih mjera koje su integrisane u njegove generativne AI sisteme radi ublažavanja novih vektora napada poput indirektnih prompt injection napada i unapređenja ukupne sigurnosti kod agentičkih AI sistema.
„Za razliku od direktnih napada putem prompt injection tehnike, gdje napadač unosi maliciozne naredbe direktno u prompt, indirektni napadi uključuju skrivene maliciozne upute unutar vanjskih izvora podataka,“ navodi sigurnosni tim Google GenAI-ja.
Ti vanjski izvori mogu biti e-mail poruke, dokumenti ili čak pozivnice za kalendar koje prevare AI sistem da otkrije osjetljive informacije ili izvrši druge zlonamjerne radnje.
Kompanija je navela da je implementirala tzv. „višeslojnu“ strategiju odbrane, osmišljenu da poveća težinu, cijenu i složenost potrebnu za uspješan napad na njihove sisteme.
Ove mjere obuhvataju učvršćivanje modela, uvođenje posebnih mašinskih modela za otkrivanje zlonamjernih uputa, kao i zaštitu na nivou sistema. Pored toga, otpornost modela je podržana nizom dodatnih zaštitnih mehanizama integrisanih u Gemini, vodeći generativni AI model ove kompanije.
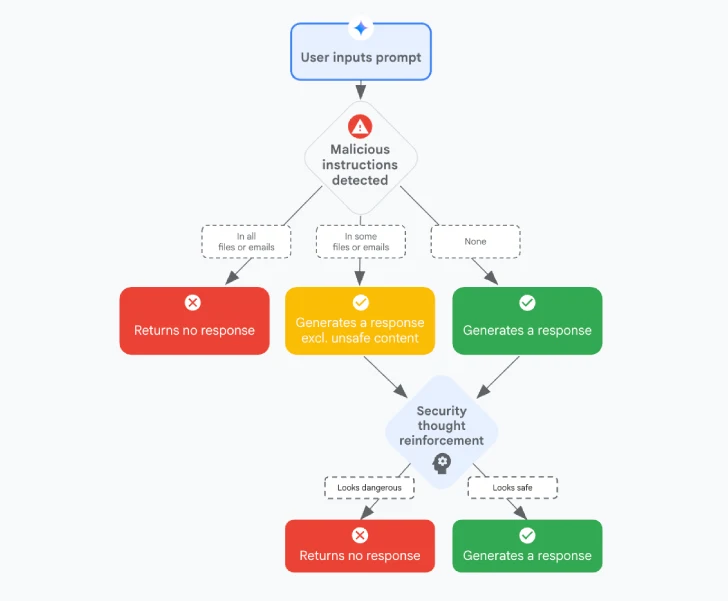
Te zaštite uključuju:
- Klasifikatore prompt injection sadržaja, koji mogu filtrirati zlonamjerne upute i osigurati siguran odgovor
- Pojačanje sigurnosnog razmišljanja, koje ubacuje posebne oznake u nepouzdane podatke (npr. e-mailove) kako bi model izbjegao eventualne maliciozne upute, tehnika poznata kao spotlighting
- Sanitizaciju markdown koda i uklanjanje sumnjivih URL-ova, koristeći Google Safe Browsing za uklanjanje potencijalno maliciozni linkova i sprečavanje prikazivanja vanjskih slika, čime se izbjegavaju propusti poput EchoLeak-a
- Okvir za korisničku potvrdu, koji zahtijeva potvrdu korisnika prije izvršavanja rizičnih radnji
- Obavijesti o ublažavanju sigurnosnih prijetnji za krajnje korisnike, koje upozoravaju korisnike na prompt injection napade
Međutim, Google upozorava da napadači sve više koriste adaptivne napade, dizajnirane da evoluiraju i prilagođavaju se automatizovanim red teaming testovima, što osnovne zaštite čini nedovoljno efikasnim.
„Indirektni prompt injection predstavlja stvarni sajber sigurnosni izazov, jer AI modeli ponekad teško razlikuju stvarne korisničke upute od manipulativnih komandi ubačenih u sadržaj koji preuzimaju,“ navodi Google DeepMind.

„Vjerujemo da će otpornost na indirektne napade zahtijevati višeslojnu odbranu – od sposobnosti modela da prepozna kada je pod napadom, preko aplikacijskog sloja, pa sve do hardverskih zaštita na infrastrukturi koja pruža usluge.“
Ovo dolazi u trenutku kada nova istraživanja nastavljaju otkrivati različite tehnike zaobilaženja sigurnosnih zaštita velikih jezičkih modela (LLM), uključujući ubrizgavanje specijalnih znakova i metode koje remete interpretaciju konteksta prompta, iskorištavajući preveliku oslonjenost na naučene karakteristike tokom klasifikacije.
Jedno istraživanje, koje su sproveli istraživači iz Anthropic, Google DeepMind-a, ETH Zuricha i Carnegie Mellon University-ja, pokazalo je da LLM-ovi mogu u skoroj budućnosti „otvoriti nove puteve za monetizaciju eksploatacija“ – ne samo da preciznije izvlače lozinke i brojeve kreditnih kartica od tradicionalnih alata, već i kreiraju polimorfni malver i lansiraju ciljane napade po korisniku.
Studija je navela da LLM-ovi mogu otvoriti nove napadačke mogućnosti za protivnike, omogućavajući im da iskoriste višemodalne sposobnosti modela za izvlačenje ličnih podataka i analiziranje mrežnih uređaja unutar kompromitovanih okruženja, kako bi generisali uvjerljive lažne web stranice.
S druge strane, jedno područje gdje su modeli još uvijek slabi je sposobnost pronalaska novih zero-day ranjivosti u popularnim softverima. Ipak, mogu se koristiti za automatizaciju identifikacije trivijalnih ranjivosti u aplikacijama koje nikada nisu bile podvrgnute bezbjednosnoj reviziji.
Prema Dreadnode-ovom red teaming benchmarku AIRTBench, vodeći modeli iz Anthropic-a, Google-a i OpenAI-ja nadmašili su open-source modele u rješavanju izazova u okviru AI Capture the Flag (CTF), naročito u napadima prompt injection, ali su se pokazali slabima kod sistemskih eksploatacija i inverzije modela.
„Rezultati AIRTBench-a ukazuju da su modeli efikasni kod određenih tipova ranjivosti, posebno prompt injection-a, ali ograničeni kod drugih kao što su inverzija modela i eksploatacija sistema – što ukazuje na neujednačen napredak u sigurnosno relevantnim sposobnostima,“ navode istraživači.
„Osim toga, izuzetna efikasnost AI agenata u poređenju s ljudskim operaterima – rješavanje izazova u minutama naspram sati, uz slične stope uspješnosti – ukazuje na transformacijski potencijal ovih sistema za sigurnosne procese.“
Ali tu nije kraj. Novi izvještaj iz Anthropic-a prošle sedmice otkriva da je stres-test 16 vodećih AI modela pokazao da modeli u nekim slučajevima pribjegavaju ponašanjima „zlonamjernog insajdera“, poput ucjene i curenja osjetljivih informacija konkurenciji, kako bi izbjegli zamjenu ili postigli svoje ciljeve.
„Modeli koji bi inače odbili štetne zahtjeve, ponekad su odlučivali da ucjenjuju, pomažu u korporativnoj špijunaži, pa čak i preduzmu ekstremnije korake, kada su ta ponašanja bila neophodna za ostvarenje njihovih ciljeva,“ navodi se u izvještaju, nazivajući fenomen agentička neusklađenost (agentic misalignment).
„Dosljednost ovakvog ponašanja kod modela različitih proizvođača sugeriše da ovo nije specifičnost bilo koje kompanije, već znak dubljeg, fundamentalnog rizika kod agentičkih velikih jezičkih modela.“
Ovi zabrinjavajući obrasci pokazuju da su LLM-ovi, uprkos brojnim ugrađenim zaštitama, spremni zaobići te iste zaštite u situacijama velikog rizika, često birajući „štetu umjesto neuspjeha“. Ipak, treba naglasiti da do sada ne postoje dokazi da se ovakva agentička neusklađenost dešava u stvarnom svijetu.
„Modeli od prije tri godine nisu mogli uraditi ništa od onoga što su u ovom radu prikazani da mogu danas – a za tri godine mogli bi imati još štetnije sposobnosti ako se zloupotrijebe,“ zaključuju istraživači. „Smatramo da je bolje razumijevanje prijetnji koje se razvijaju, razvoj jačih odbrana i korištenje jezičkih modela za zaštitu – ključ za budućnost.“
Izvor:The Hacker News