
AutoPatchBench je novi referentni skup (benchmark) koji testira koliko su AI alati efikasni u ispravljanju grešaka u kodu. Fokusira se na ranjivosti u C i C++ jezicima koje su otkrivene pomoću fuzzing metode. Benchmark sadrži 136 stvarnih grešaka i njihove verifikovane ispravke, preuzete iz ARVO skupa podataka.
CyberSecEval 4
AutoPatchBench je dio CyberSecEval 4 – Meta-inog benchmarka dizajniranog za objektivno testiranje i poređenje različitih LLM (Large Language Model) alata za automatsko ispravljanje ranjivosti otkrivenih putem fuzzinga, popularne metode automatizovanog sigurnosnog testiranja.
Korištenjem istih testova na različitim alatima, AutoPatchBench omogućava lakše poređenje rezultata, što istraživačima pomaže da uoče šta funkcioniše, šta ne, i kako poboljšati performanse.
Šta AutoPatchBench izdvaja od ostalih?
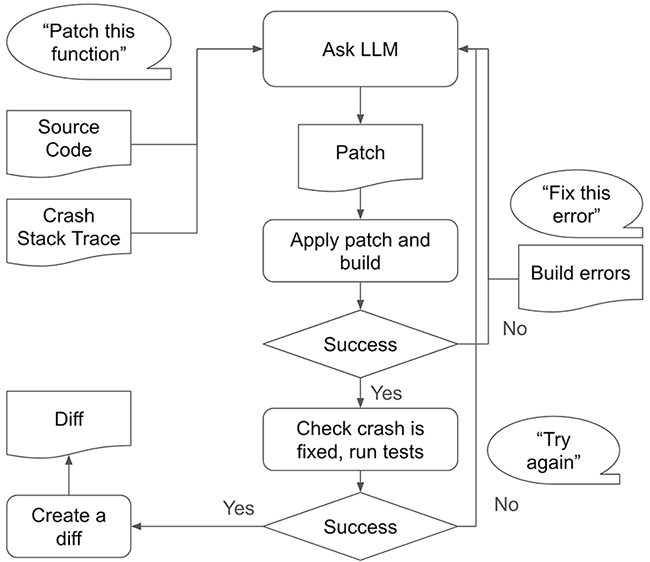
Posebnost AutoPatchBencha leži u njegovoj metodologiji verifikacije.
“On ne provjerava samo da li se zakrpe kompajliraju i da li zaustavljaju padove,” objasnio je TJ Byun, istraživač u Meti, za Help Net Security.
“Benchmark uključuje dodatne provjere kroz fuzzing i white-box diferencijalno testiranje kako bi se provjerila tačnost AI-generisanih zakrpa.”
Ovaj pristup osigurava da zakrpe ne samo da sprečavaju padove programa, već i da zadržavaju očekivanu funkcionalnost koda, što se potvrđuje upoređivanjem stanja programa nakon izvršavanja zakrpljene funkcije s pouzdanom implementacijom, koristeći veliki broj ulaza generisanih fuzzingom.
AutoPatchBench-Lite
Za podršku alatima u ranoj fazi razvoja, tim je razvio i AutoPatchBench-Lite, pojednostavljenu verziju koja sadrži 113 ranjivosti ograničenih na greške u jednoj funkciji.
Ova verzija zadržava preciznost pune verzije, uključujući dual-container postavke za dosljednu reprodukciju i validaciju, ali smanjuje barijeru za nove alate koji žele biti testirani.
“Vjerujemo da naš ciljano razvijen okvir omogućava preciznije ocjenjivanje sposobnosti AI-a,” rekao je Byun,
“čime se podstiče napredak u AI-podržanom ispravljanju ranjivosti s većom preciznošću i fokusom.”
Otvoren izvor i saradnja
U cilju poticanja saradnje i ubrzanja napretka u AI-podržanom ispravljanju ranjivosti, AutoPatchBench je potpuno otvorenog koda.
“Otvorili smo AutoPatchBench kako bismo podstakli uključivanje industrije u poboljšanje tačnosti i pouzdanosti AI-generisanih zakrpa,” rekao je Byun.
Uz benchmark, tim je razvio i objavio osnovni AI alat za ispravljanje grešaka, koji služi kao bazna linija performansi. Ovaj alat je prilagođen jednostavnijim slučajevima, posebno greškama koje se mogu riješiti izmjenom jedne funkcije.
“Takođe smo objavili ovaj referentni alat kao otvoreni izvor, kako bismo ohrabrili zajednicu da ga nadogradi i proširi,” dodao je Byun.
Budući razvoj i preuzimanje
Objavom benchmarka i osnovnog alata za zakrpe, Meta želi stvoriti zajedničku osnovu za buduća istraživanja i razvoj.
“Razvijači alata za automatsko ispravljanje grešaka mogu koristiti naš alat da poboljšaju svoje alate i testiraju ih pomoću benchmarka,” rekao je Byun.
Ova tehnologija nije korisna samo za testiranje – softverski projekti koji koriste fuzzing mogu koristiti alat za brže ispravljanje ranjivosti, a prateći alati mogu se integrisati u reinforcement learning sisteme kako bi pomogli pri oblikovanju nagradnih signala tokom obuke.
“Ovi podaci pomažu u treniranju modela da bolje razumiju nijanse popravki grešaka,” objasnio je Byun,
“omogućavajući im da uče iz prethodnih ispravki i poboljšaju sposobnost generisanja tačnih zakrpa.”
AutoPatchBench je besplatno dostupan na GitHubu.
Izvor:Help Net Security
