
Meta je u utorak najavila LlamaFirewall, okvir otvorenog koda dizajniran za zaštitu sistema vještačke inteligencije (AI) od novih sajber prijetnji, poput pokušaja injekcija kroz upite, jailbreakova i nesigurnog koda, između ostalog.
Prema riječima kompanije, okvir uključuje tri zaštitne mjere, uključujući PromptGuard 2, Provjere usklađenosti agenata i CodeShield.
PromptGuard 2 je dizajniran za detektovanje pokušaja jailbreaka i injekcija upita u realnom vremenu, dok Provjere usklađenosti agenata mogu da ispituju razmišljanje agenata u vezi sa mogućim otmicama ciljeva i indirektnim scenarijima injekcija upita.
CodeShield se odnosi na online statički analitički alat koji ima za cilj sprječavanje generisanja nesigurnog ili opasnog koda od strane AI agenata.
“LlamaFirewall je izgrađen da služi kao fleksibilni, zaštitni okvir u realnom vremenu za osiguranje aplikacija koje koriste LLM,” navodi se u opisu projekta na GitHubu.
“Njegova arhitektura je modularna, omogućavajući bezbjednosnim timovima i programerima da sastave složene odbrambene mjere koje se protežu od unosa sirovih podataka do finalnih izlaznih akcija – kroz jednostavne modele za čat i kompleksne autonomne agente.”
Pored LlamaFirewall-a, Meta je omogućila i ažurirane verzije LlamaGuard i CyberSecEval, kako bi se bolje detektovali različiti uobičajeni tipovi sadržaja koji krše bezbjednosne smjernice i mjere odbrambene mogućnosti AI sistema.
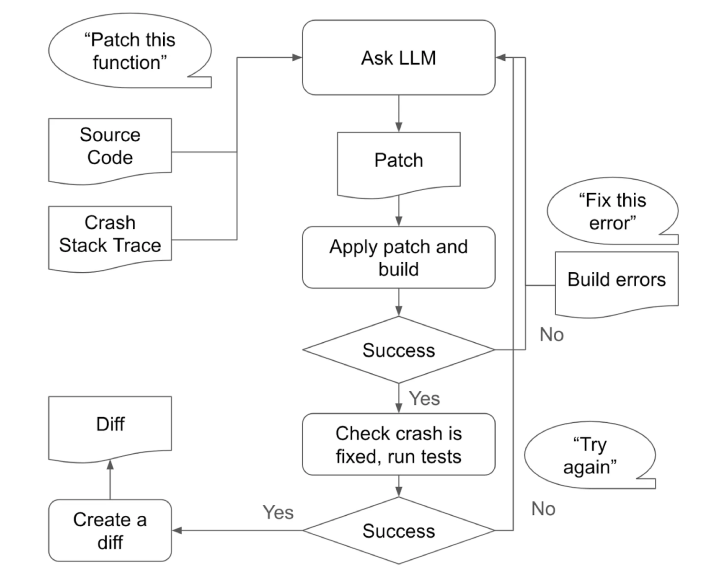
CyberSecEval 4 takođe uključuje novi benchmark pod nazivom AutoPatchBench, koji je dizajniran da procijeni sposobnost velikih jezičkih modela (LLM) agenata da automatski ispravljaju širok spektar ranjivosti u C/C++ kodu identifikovanih putem fuzzinga, pristupa poznatog kao AI-pomoćno zakrpljivanje.
“AutoPatchBench pruža standardizovani okvir za procjenu efikasnosti alata za ispravku ranjivosti uz pomoć AI,” navodi kompanija. “Ovaj benchmark ima za cilj olakšavanje sveobuhvatnog razumijevanja sposobnosti i ograničenja različitih pristupa temeljenih na AI za ispravljanje grešaka pronađenih fuzzing metodama.”
Na kraju, Meta je lansirala novi program pod nazivom Llama za Odbranu, kako bi pomogla partnerskim organizacijama i AI programerima da pristupe otvorenim, ranim pristupima i zatvorenim AI rješenjima za adresiranje specifičnih bezbjednosnih izazova, kao što je detekcija AI-generisanog sadržaja koji se koristi u prevarama, lažnim predstavljanjima i phishing napadima.
Ova najava dolazi nakon što je WhatsApp prikazao novu tehnologiju pod nazivom Private Processing koja omogućava korisnicima da koriste AI funkcionalnosti bez ugrožavanja njihove privatnosti prebacujući zahtjeve na sigurno, povjerljivo okruženje.
“Radimo sa bezbjednosnom zajednicom na auditu i poboljšanju naše arhitekture i nastavićemo da razvijamo i jačamo Private Processing u otvorenom okruženju, u saradnji sa istraživačima, prije nego što ga lansiramo u proizvod,” navodi Meta.
Izvor: The Hacker News
